You will need
- hydrometer, sulfuric acid or a concentrated electrolyte, the charger.
Instruction
1
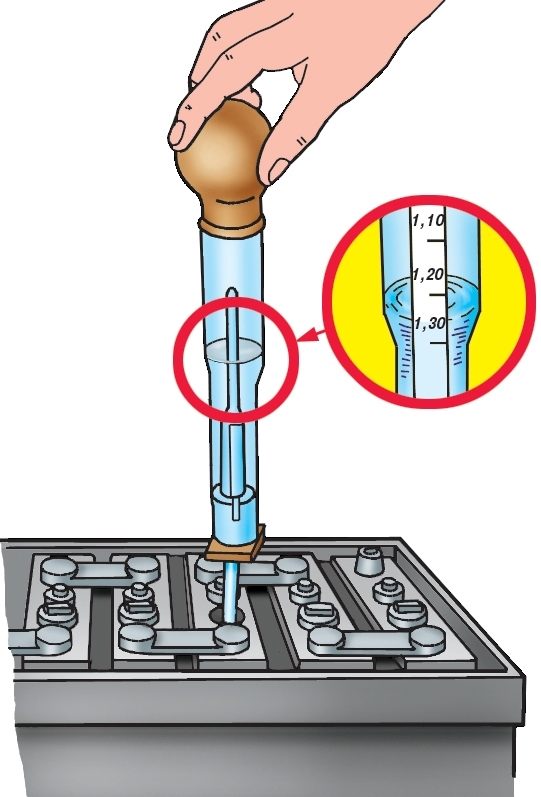
Raising the density of the electrolyte without topping up kislotoupornymi a symptom of the fall of the density of the electrolyte is discharging. To determine the density use the hydrometer. To do this with it, pull a certain amount of the electrolyte and on the pop-up floats, determine its density. It should be of 1.27 g/cm3, in the winter it may be a bit higher. If the density of the electrolyte is less than normal, connect the battery to the charger and charge it until until the electrolyte in the banks do not boil. Then drain it using the bulb, during this time, measure the discharge current and its time. Multiplying these values, find out the capacity of the battery and compare it with the passport. If it is more than 30% less, then reloading will not help. Otherwise, charge the battery pack again and measure the density of the electrolyte. It should be OK.
2
Raising the density of electrolyte by adding kisloty if the first method didn't help, and the density of the electrolyte is less than 1,27 g/cm3 dilute acid. To do this, a hydrometer, pull a certain amount of the electrolyte and pour the sulfuric acid. Note that it has a density of 1.83 g/cm3, and it is very corrosive. Car shops for sale the concentrate of the electrolyte density of 1.4 g/cm3, it is more secure, so better use it. Add the concentrate, while the density does not increase to the desired value. After that, check the battery charging with a small current (not more than 2 (A) for half an hour. During this time the electrolyte is fully mixed. Again check the density in all banks. It should be the same and conform to the standards. If the density is still low, repeat the operation again.
3
Observe special caution when working with sulfuric acid. Avoid its contact with skin or clothing. If this occurs, wash out electrolyte with plenty of water and treat the place with a solution of soda, which neutralizes acid. When pulling the solution in any case, do not invert the battery, because the slime from the plates can short-circuit the battery, and it will deteriorate.


